Multiplier uncertainty
In macroeconomics, multiplier uncertainty is lack of perfect knowledge of the multiplier effect of a particular policy action, such as a monetary or fiscal policy change, upon the intended target of the policy. For example, a fiscal policy maker may have a prediction as to the value of the fiscal multiplier—the ratio of the effect of a government spending change on GDP to the size of the government spending change—but is not likely to know the exact value of this ratio. Similar uncertainty may surround the magnitude of effect of a change in the monetary base or its growth rate upon some target variable, which could be the money supply, the exchange rate, the inflation rate, or GDP.
There are several policy implications of multiplier uncertainty: (1) If the multiplier uncertainty is uncorrelated with additive uncertainty, its presence causes greater cautiousness to be optimal (the policy tools should be used to a lesser extent). (2) In the presence of multiplier uncertainty, it is no longer redundant to have more policy tools than there are targeted economic variables. (3) Certainty equivalence no longer applies under quadratic loss: optimal policy is not equivalent to a policy of ignoring uncertainty.
Contents |
Effect of multiplier uncertainty on the optimal magnitude of policy
For the simplest possible case,[1] let P be the size of a policy action (a government spending change, for example), let y be the value of the target variable (GDP for example), let a be the policy multiplier, and let u be an additive term capturing both the linear intercept and all unpredictable components of the determination of y. Both a and u are random variables (assumed here for simplicity to be uncorrelated), with respective means Ea and Eu and respective variances 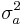 and
and 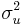 . Then
. Then
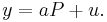
Suppose the policy maker cares about the expected squared deviation of GDP from a preferred value 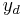 ; then its loss function L is quadratic so that the objective function, expected loss, is given by:
; then its loss function L is quadratic so that the objective function, expected loss, is given by:
![\text{E}L = \text{E}(y-y_d)^2 = \text{E}(aP %2B u - y_d)^2 = [\text{E}(aP %2B u - y_d)]^2 %2B \text{var} (aP %2B u - y_d) = [(\text{E}a)P %2B \text{E}u - y_d]^2 %2B P^2 \sigma^2_a %2B \sigma^2_u.](/2012-wikipedia_en_all_nopic_01_2012/I/71471c5aa86b247b41bae3b96206fbba.png)
Optimizing with respect to the policy variable P gives the optimal value Popt:
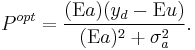
Here the last term in the numerator is the gap between the preferred value yd of the target variable and its expected value Eu in the absence of any policy action. If there were no uncertainty about the policy multiplier, would be zero, and policy would be chosen so that the contribution of policy (the policy action P times its known multiplier a) would be to exactly close this gap, so that with the policy action Ey would equal yd. However, the optimal policy equation shows that, to the extent that there is multiplier uncertainty (the extent to which 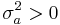 ), the magnitude of the optimal policy action is diminished.
), the magnitude of the optimal policy action is diminished.
Thus the basic effect of multiplier uncertainty is to make policy actions more cautious, although this effect can be modified in more complicated models.
Multiple targets or policy instruments
The above analysis of one target variable and one policy tool can readily be extended to multiple targets and tools.[2] In this case a key result is that, unlike in the absence of multiplier uncertainty, it is not superfluous to have more policy tools than targets: with multiplier uncertainty, the more tools are available the lower expected loss can be driven.
Analogy to portfolio theory
There is a mathematical and conceptual analogy between, on the one hand, policy optimization with multiple policy tools having multiplier uncertainty, and on the other hand, portfolio optimization involving multiple investment choices having rate-of-return uncertainty.[2] The usages of the policy variables correspond to the holdings of the risky assets, and the uncertain policy multipliers correspond to the uncertain rates of return on the assets. In both models, mutual fund theorems apply: under certain conditions, the optimal portfolios of all investors regardless of their preferences, or the optimal policy mixes of all policy makers regardless of their preferences, can be expressed as linear combinations of any two optimal portfolios or optimal policy mixes.
Dynamic policy optimization
The above discussion assumed a static world in which policy actions and outcomes for only one moment in time were considered. However, the analysis generalizes to a context of multiple time periods in which both policy actions take place and target variable outcomes matter, and in which time lags in the effects of policy actions exist. In this dynamic stochastic control context with multiplier uncertainty,[3][4][5] a key result is that the "certainty equivalence principle" does not apply: while in the absence of multiplier uncertainty (that is, with only additive uncertainty) the optimal policy with a quadratic loss function coincides with what would be decided if the uncertainty were ignored, this no longer holds in the presence of multiplier uncertainty.
References
- ^ Brainard, William (1967). "Uncertainty and the effectiveness of policy". American Economic Review 57 (2): 411–425. JSTOR 1821642.
- ^ a b Mitchell, Douglas W. (1990). "The efficient policy frontier under parameter uncertainty and multiple tools". Journal of Macroeconomics 12 (1): 137–145. doi:10.1016/0164-0704(90)90061-E.
- ^ Chow, Gregory P. (1976). Analysis and Control of Dynamic Economic Systems. New York: Wiley. ISBN 0471156167.
- ^ Turnovsky, Stephen (1976). "Optimal stabilization policies for stochastic linear systems: The case of correlated multiplicative and additive disturbances". Review of Economic Studies 43 (1): 191–194. JSTOR 2296741.
- ^ Turnovsky, Stephen (1974). "The stability properties of optimal economic policies". American Economic Review 64 (1): 136–148. JSTOR 1814888.